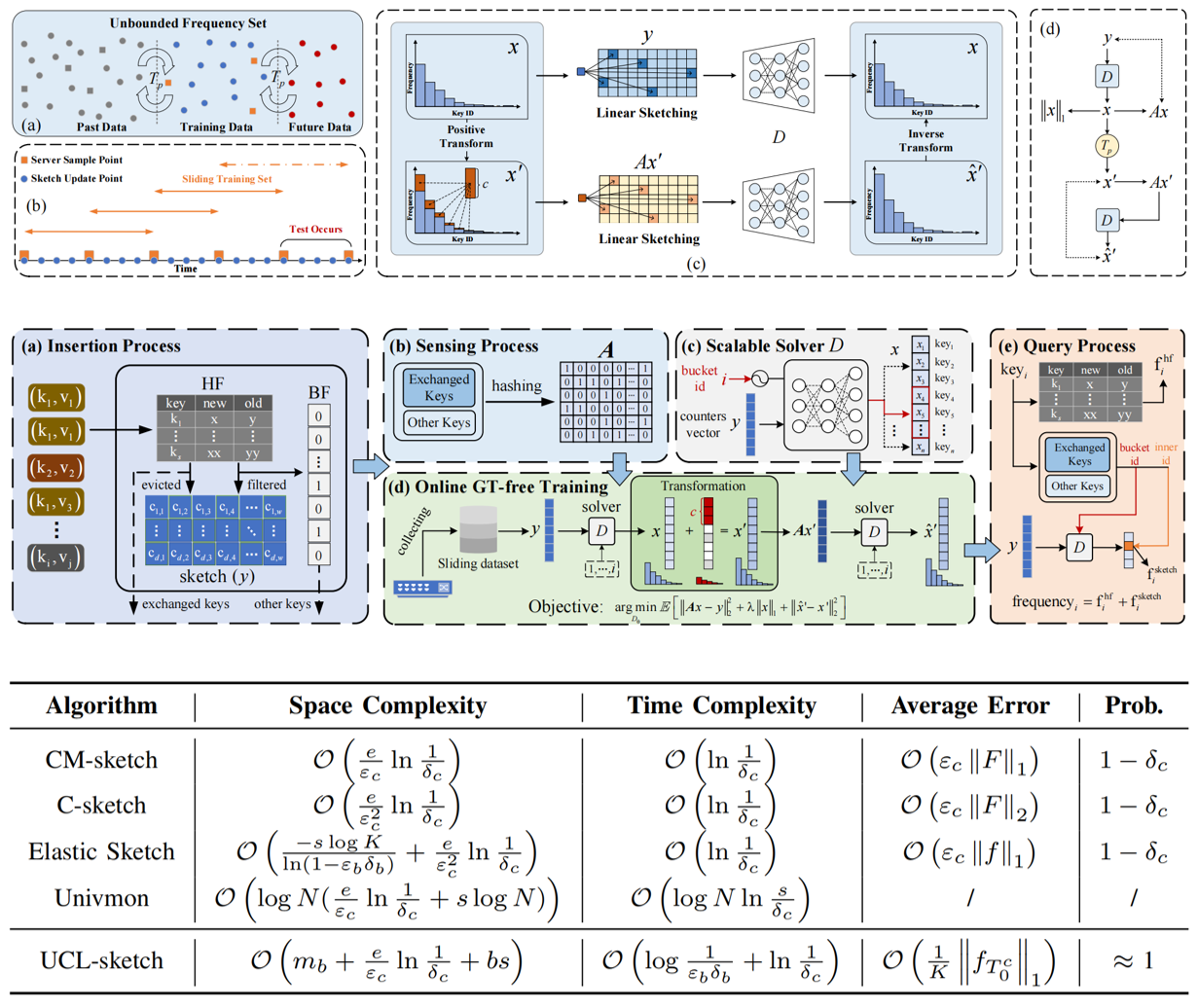
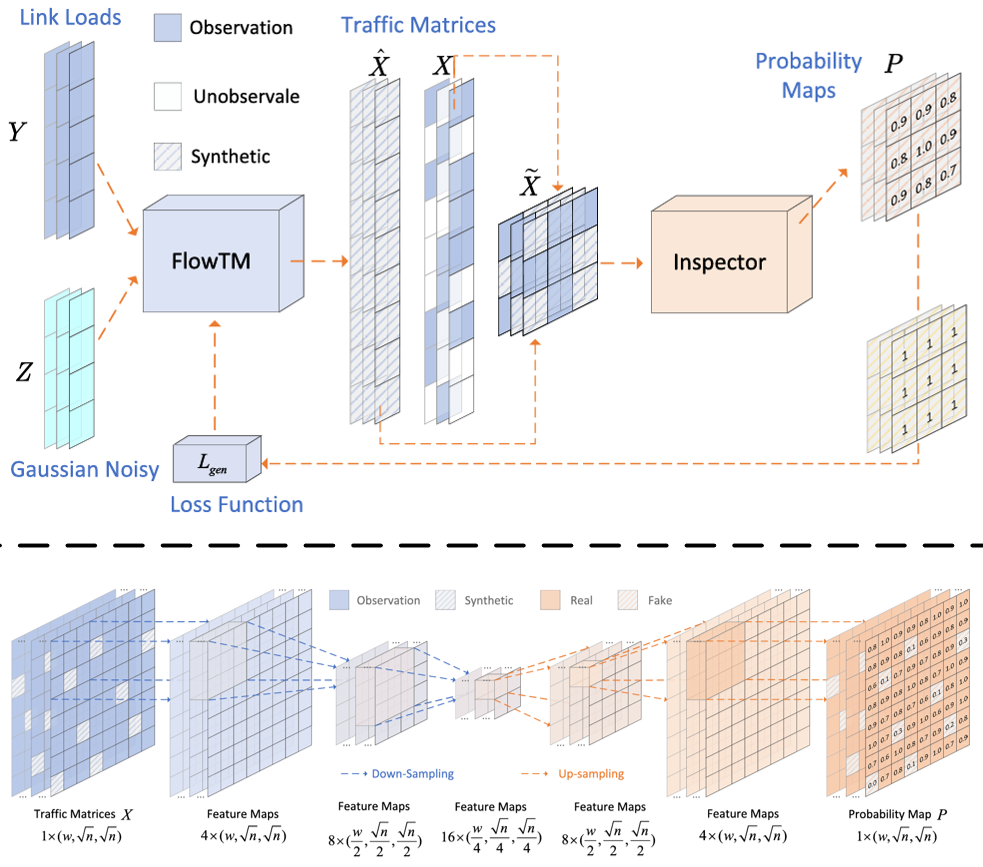
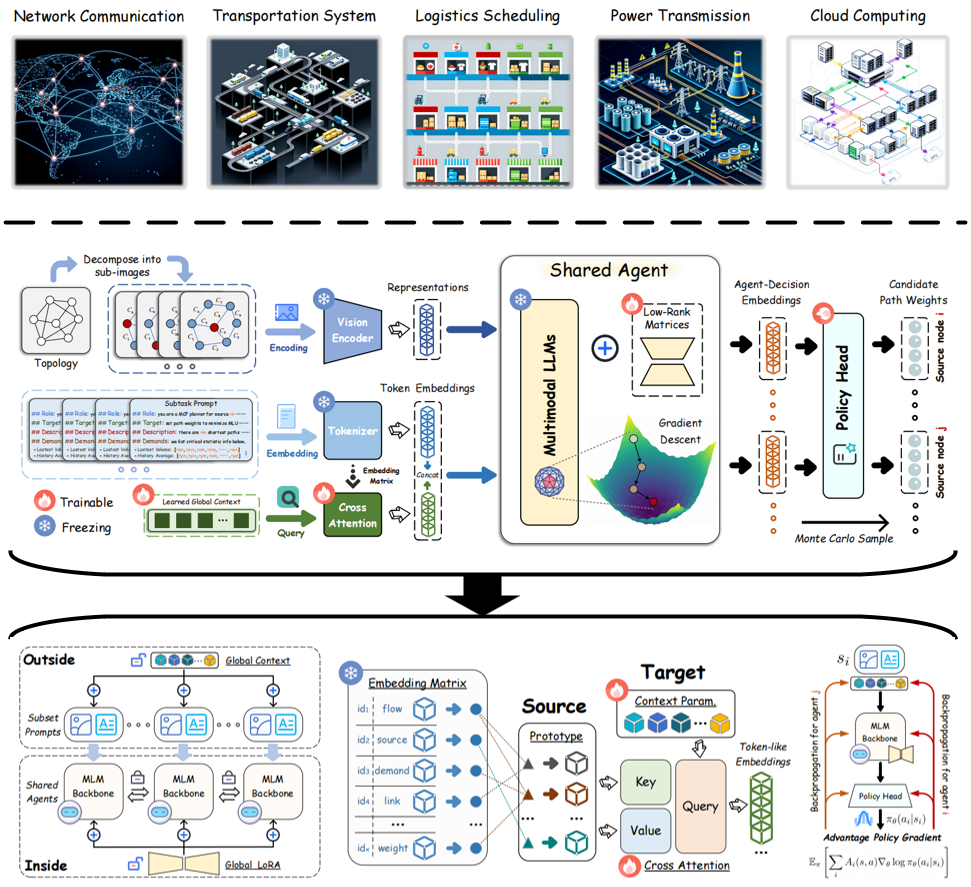
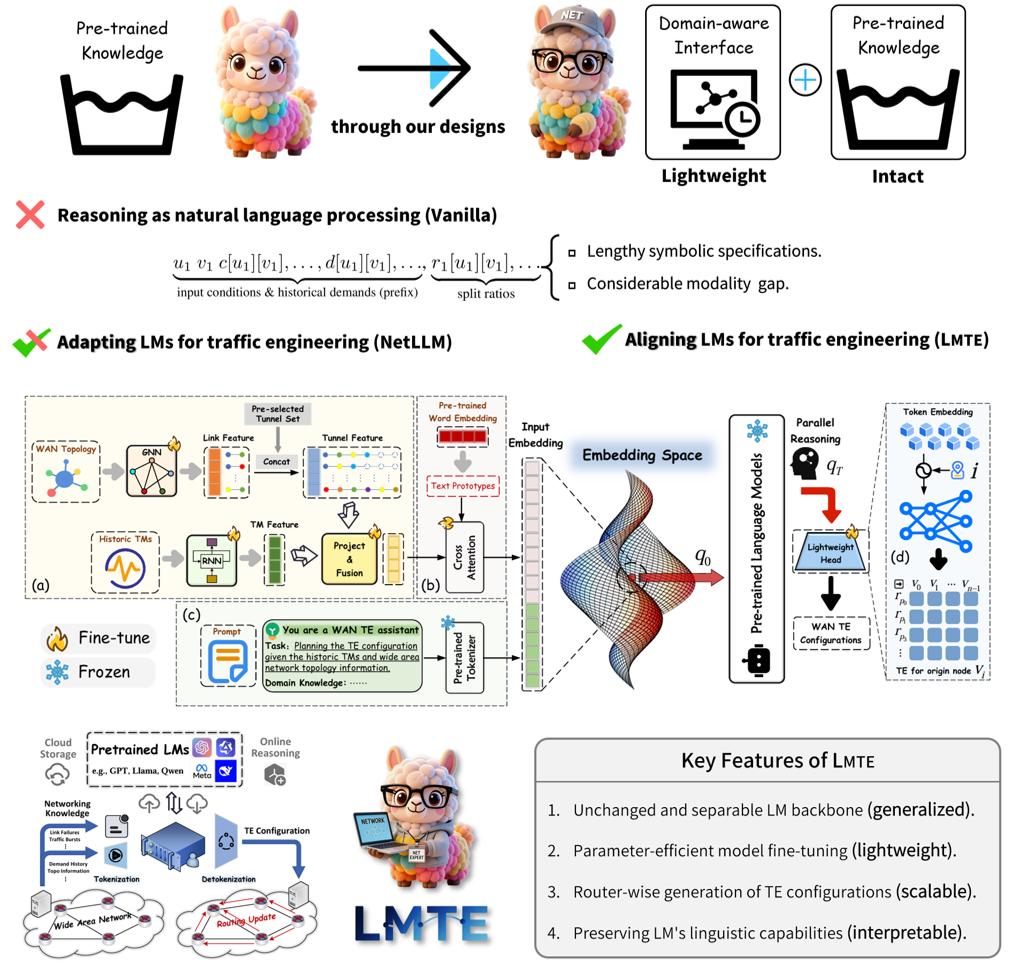
Learning-based Sketches for Frequency Estimation in Data Streams without Ground Truth
Xinyu Yuan
Ph.D. student, College of Computer Science and Technology, Zhejiang University
Email: yxy5315@gmail.com

Education
I am pursuing my Ph.D. at Zhejiang University, where I am part of the ArcLab research group led by Prof. Wenzhi Chen.
Before that, I received my M.Eng. and B.Eng. from the School of Artificial Intelligence at Hefei University of Technology and School of Information and Artificial Intelligence at Anhui Agricultual University respectively, advised by Assoc. Prof. Yan Qiao.
Download my CV
Research
My primary research interests include network systems, machine learning, AI-generated content (AIGC) and embodied intelligence. I am actively working on (networking) services computing and applications empowered by machine learning. I am also working on studying powerful generative models, e.g., diffusions and LLMs.